Apis High Availability
Introduction
The Apis High Availability concept is designed on basis the principles described in OPC UA Part 4 (Services). Apis supports non-transparent redundancy with hot failover mode, meaning that the nodes of the cluster do not exchange information or state, but operates on standalone basis, continuously connected to the underlying systems to update internal state and history. In addition to the general principles of OPC UA Client/Server redundancy described in OPC UA Part 4, Apis features concepts for config synchronization and history synchronization based on proprietary Apis technology and definitions. The high availability concept can be used to achieve both redundancy and load balancing.
OPC UA non-transparent redundancy
Non-transparent redundancy means that clients themselves identify what servers are available in the redundant server set. Servers expose information which tells the clients what modes of failover the server supports together with the current state (service level) of the server, and endpoint information of other servers in the cluster. This information allows the clients to determine what actions it may need to take to accomplish failover.
OPC UA hot failover mode
All Servers in the redundant server set are powered-on and are up and running. In scenarios where Servers acquire data from a downstream device, such as a PLC, then all servers are actively connected to the downstream device(s) in parallel. The Servers have minimal knowledge of the other servers in their group and are independently functioning. When a server fails or encounters a serious problem then its service level drops, which allows the clients to select another server in the server set. On recovery, the server returns to the redundant server set with an appropriate service level to indicate that it is available.
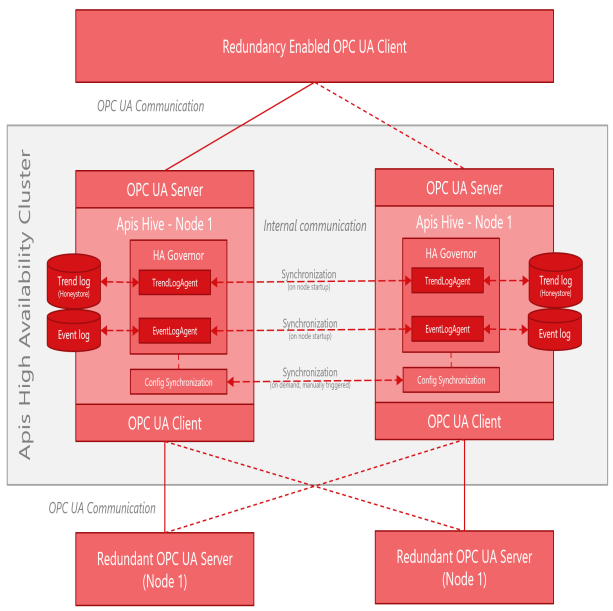
Apis Clustering
An Apis High Availability Node consists of an Apis Hive Instance with associated event databases and trend databases (Honeystore databases and Honeystore service). An Apis High Availability Cluster is defined by ApisHAGovernor (singleton Apis module) modules configured in the Apis Hive nodes (instances) constituting the cluster. Each node of the cluster is, in normal situations, connected to underlying sources (redundant or non-redundant), exposes real-time data and history from the underlying sources and logs and stores time series and events from the underlying sources to the databases associated with the node. The ApisHAGovernors are aware of their peers in the other nodes of the Apis Cluster and governs the synchronization of historical data between the nodes at startup of the node.
Inbound interfaces
For inbound interfaces, failover is handled by the OPC UA Client Modules and Connection Manager module, which monitors the service levels of connected redundant sources. The Apis OPC UA client module relays to the Connection Manager bee for connection information. The Connection manager bee maintains ServerURI arrays from underlying servers and selects proper server connection based of the service level exposed by the different servers in the cluster.
Outbound interface
On the outbound OPC UA Server interface, the service level of the Apis Hive instance is exposed, together with connection information to the peers of the cluster. The Apis OPC UA server exposes OPC UA redundancy related concepts such as RedundancySupport, ServiceLevel and ServerURI array. This allows connected clients to failover to other nodes in the Apis High Availability Cluster. It is up to the deployment project to define the algorithm for computing service level.
Synchronization of configuration
The configuration of the cluster nodes is synchronized as a manual triggered action, where the configuration is distributed from the config master node to other nodes in the cluster. When configuring or applying changes to the cluster, one of the nodes is promoted to config master. The config master node is then configured (either directly using AMS or import mechanisms or by migrating config from an engineering server). When the config master is configured/reconfigured, the other nodes are cloned from the config master node. Cloning of cluster nodes is based on server cloning pattern using Backup-Restore features of Apis.
Synchronization of historical data
Trend log and Event log agents are responsible, on behalf of the governor (ApisHAGovernor module), to keep the trend log and event log databases of the cluster nodes similar. The trend logs and event logs of the cluster nodes are not expected to be bit-equal, but the goal is to be able to extract similar logs from both servers and avoid major log gaps due to cluster node downtime. The log agents will keep track of a LastKnownGoodHistoryTime at all time, and update this whenever the history is considered good. On startup of a cluster node after a certain downtime, the cluster node will immediately start to collect real-time events from the sources and contact other servers in the cluster to close in the trend log and event log gap between LastKnownGoodHistoryTime and the time of startup.
The data synchronization is limited to synchronizing history databases on startup of cluster nodes, to fill in the gap in history since the last time the node was fully operative. Other types of gap synchronization, e.g. as a result of downtime of separate inbound interfaces or synchronization of manual entered or altered data is expected to be supported in later product versions.